CNN에서 pooling이란?
- * 20.12.22. update, 블로그 옮겼습니다. 공교롭게도 이 블로그를 시작하자마자 취직을 해서 글을 이어쓸 수 없었네요. 이제라도 다시 시작하려고 합니다.
- https://mathmemo.tistory.com
이번 포스트는 지난 CNN의 introduction의 후속입니다. 혹시나 CNN을 잘 모르거나 헷갈리시는 분들은 여기에서 확인해보시기 바랍니다.
김성훈교수님의 강의에서는 Pooling을 다음과 같이 정의합니다:
Convolution을 거쳐서 나온 activation maps이 있을 때,
이를 이루는 convolution layer을 resizing하여 새로운 layer를 얻는 것

하지만 다른 강의에서는 pooling을 convolution의 후속과정이 아닌 별도의 개념으로 정의합니다. 예를 들어 convolution을 matrix 연산에 의해 얻는 것이라면, pooling은 matrix 연산을 사용하지 않고 각 pixel에서 하나의 값을 뽑아내는 과정으로도 이해할 수 있습니다. (령우피셜)
이러한 pooling에는 최댓값을 뽑아내는 max pooling, 평균값을 뽑아내는 mean pooling등 다양한 종류가 있습니다. 그 중에서 강연 중 예를 들고 있는 max pooling에 대해 알아보도록 하겠습니다.
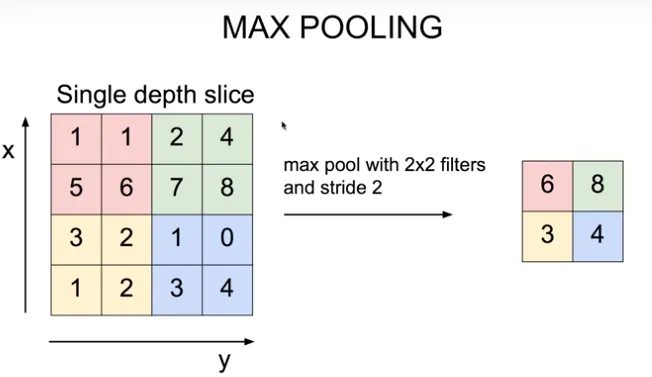
위와 같은 data가 주어져있다고 해봅시다. 여기서 우리는 stride가 2일 때 2x2 filter를 통하여 max pooling을 하려고 합니다. 방법은 아주 간단합니다. 첫 번째 빨간색 사각형 안의 숫자 1,1,5,6 중에서 가장 큰 수인 6을 찾습니다. 다음 초록색 사각형 안의 숫자인 2,4,7,8 중에서 가장 큰 수인 8을 찾고… 이와 같은 과정을 반복하면 오른쪽의 상자 6,8,3,4를 얻을 수 있습니다. 간단하죠?
그렇다면 이와 같은 pooling은 왜 하는 걸까요? 이유는 바로 overfitting을 방지하기 위함인데요, 예를 들어 설명해 보겠습니다. 이 예는 이 링크를 번역한 것입니다. cs231n 강의에서는 어떻게 정의하는지 잘 모르겠지만, 우선 제 블로그에서는 feature와 parameter를 다음과 같이 약속하도록 하겠습니다.
feature := elements of input data
parameter := elements of weight matrix
우리에게 size가 96x96인 image가 주어져 있고(즉, feature의 수는 96x96개), 이를 400개의 filter로 convolution한 size 8x8x400의 convolution layers가 있습니다. 이 포스트에서 밝힌 바와 같이 각 convolution layer에는 (stride를 1이라 가정하면) (96–8+1)x(96–8+1)=89x89=7921개의 feature가 있고, 이런 layer가 400개이니 총 feature의 수는 89x89x400=3,168,400개가 됩니다. 이렇게 feature가 많아지면 overfitting의 우려가 있음은 자명합니다.
여기서 pooling을 해준다면 적절히 조절할 수 있겠죠? 그래서 padding과 pooling을 적당히 써주면 다음과 같은 사진을 얻습니다. 아주 유명한 사진입니다. 출처는 아마도 cs231n일 것입니다.(령우피셜)

그럼 이 포스트는 여기까지 하도록 하겠습니다.